承接上一篇的說明,以前都直接的用round函數(四捨六入五成雙)來處理四捨五入,
在一般的數據計算上,這種處理方式其實是比較科學的。
round函數可以在多次重複計算下,減少數據的誤差,
比我們傳統認知的四捨五入好。
但有些場合要做的是依四捨五入的定義,明確比較大小,
這時候使用round函數就是一個很大的坑了!!
但在進入主題之前,我們應該先對程式中的浮點數有一個概念,
這部份可以參考一下Python的說明文件:
浮點數運算:問題與限制
以及以下網址的說明:
Python 的 round() 與 decimal 模組
接下來可以先來看一下我創建的數據,以及使用decimal模組執行的結果:
import pandas as pd
from decimal import Decimal, ROUND_UP, ROUND_DOWN, ROUND_HALF_UP, ROUND_HALF_DOWN, ROUND_HALF_EVEN, ROUND_FLOOR, ROUND_CEILING
df = pd.DataFrame(data=[3.115, 3.225, 3.335, 3.445, 3.555, 3.665, 3.775, 3.885, 3.995], columns=['範例數據'])
df['浮點數結果'] = df['範例數據'].apply(lambda x: "{:1.20f}".format(x))
df['round結果'] = df['範例數據'].round(2)
df['ROUND_UP結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_UP))
df['ROUND_DOWN結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_DOWN))
df['ROUND_HALF_UP結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_UP))
df['ROUND_HALF_DOWN結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_DOWN))
df['ROUND_HALF_EVEN結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_EVEN))
df['ROUND_FLOOR結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_FLOOR))
df['ROUND_CEILING結果'] = df['範例數據'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_CEILING))
df
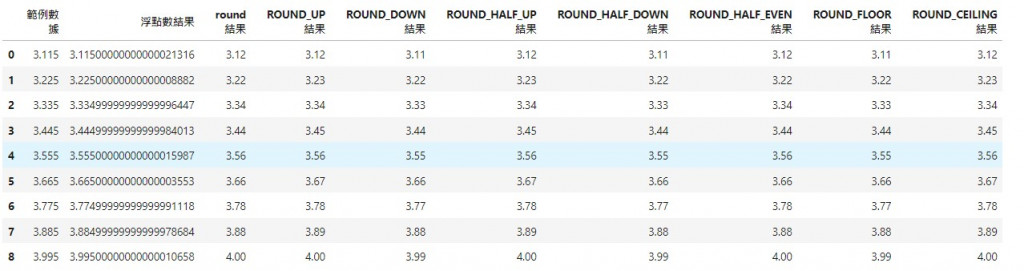
參考上面的浮點數結果,其實就是程式中真正拿來運算的值。
所以round函數其實是以最接近的值來做修整!!
因為用浮點數來運算有限制及問題,我們只能依自己的需求,
設定你要的結果。
比如說很多學校招生簡章都會說明四捨五入來計算成績,
但如果我們用了round函數,就會產生誤差,可能造成後續的糾紛。
舉例來說,招生考試的評分項目有以下二項:
「資審成績」佔總成績50%,面試成績佔總成績50%,計算方式定義如下:總成績 = 資審成績*0.5(四捨五入取至小數點第2位) + 面試成績*0.5(四捨五入取至小數點第2位)
接下來看一下程式實作的範例:
import numpy as np
import pandas as pd
from decimal import Decimal, ROUND_HALF_UP
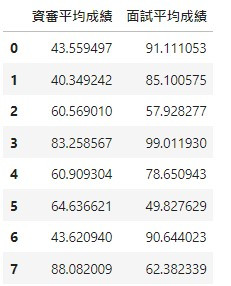
# 產生8列6欄介於0-100的DataFrame
df = pd.DataFrame(np.random.uniform(40,100,size=(8, 2)), columns=['資審平均成績', '面試平均成績'])
df
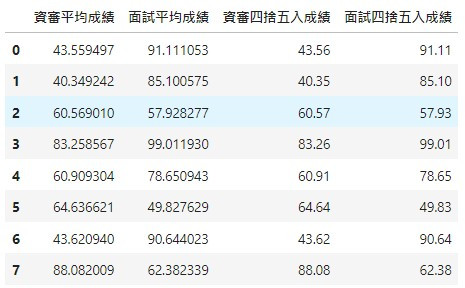
# 先用decimal模組的ROUND_HALF_UP做四捨五入取到小數點第二位
df['資審四捨五入成績'] = df['資審平均成績'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_UP))
df['面試四捨五入成績'] = df['面試平均成績'].apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_UP))
df
# 確定一下程式中四捨五入成績的浮點數值
df['資審四捨五入成績_浮點數'] = df['資審四捨五入成績'].apply(lambda x: "{:1.20f}".format(x))
df['面試四捨五入成績_浮點數'] = df['面試四捨五入成績'].apply(lambda x: "{:1.20f}".format(x))
df
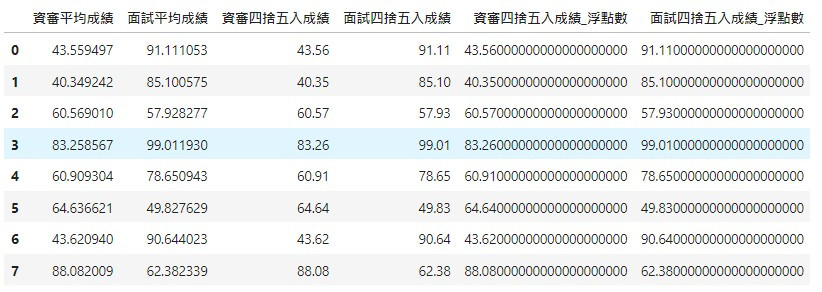
用了decimal模組後,確認程式中的浮點數和我們四捨五入的結果是一致的。
接下來可以放心的計算比例成績和總成績了。
df['資審比例成績'] = (df['資審四捨五入成績'] * 50/100).apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_UP))
df['面試比例成績'] = (df['面試四捨五入成績'] * 50/100).apply(lambda x: Decimal(str(x)).quantize(Decimal('.00'), ROUND_HALF_UP))
df['總成績'] = df['資審比例成績'] + df['面試比例成績']
df
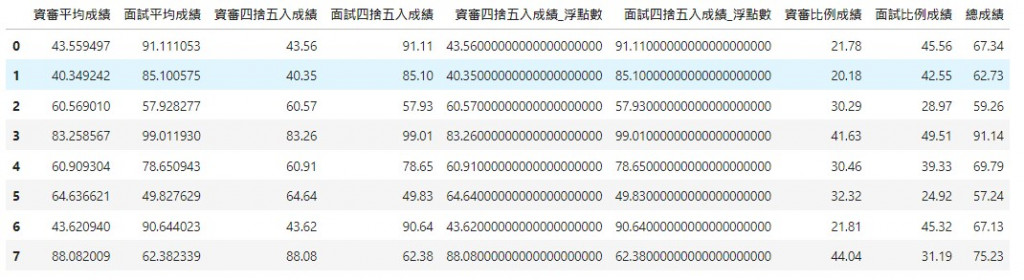
最後的結果就是我們要的四捨五入的總成績。
 mackuo
mackuo

 iThome鐵人賽
iThome鐵人賽